The Database Inside Your Codebase

Navigating codebases of any meaningful size is difficult. Most of a programmer’s time is spent jumping through the codebase, reading or skimming to build a mental model of the constructs and conventions within it. These constructs — among them: the DSLs, interfaces, and taxonomy of types that exist — are arguably the most important precursor to understanding where and how to make changes. But these constructs only exist in programmers’ heads. It’s difficult or impossible to navigate most codebases through the lens of those constructs; programmers lack “code browsers” that present the underlying code independently of files and the filesystem hierarchy. Yet code browsers that can do so — and we’ll look at some examples below — would be incredibly useful. This is because instances of these constructs can be thought of as records in a database, albeit an ad-hoc, poorly-specified database that can only be queried through carefully-crafted regexes1.
In simple cases, some constructs manifest as naming conventions: prefixes in a name may be a rudimentary way to namespace classes2, while suffixes may be a rudimentary way to group classes or identify their type3. But these are easy examples; many patterns are much more subtle.
“Where is this used?”
Imagine figuring out “where is this used?”, for various types of “this”:
Most code editors (perhaps paired with a language server) can show you where local variables are used. This usually also works for finding where methods are invoked — although perhaps less reliably in dynamic-dispatch languages, or languages without types.
What if you want to find where instances of a particular model get created? There may be multiple ways to create a model, so this isn’t super simple. In Rails, for example, there’s two built-in ways to create a model: you can either call .new to create a new instance in memory followed by .save to persist it to the database, or call .create to automatically do both. Your particular codebase might have additional wrappers for doing this that you’re supposed to use. Even worse, imagine that sometimes you create a .new instance, then set some properties on it over the next few lines, then finally call .save. Something like this:
user = User.new
user.email = 'hello@example.com' unless self.anonymous?
user.save
Conceptually, that’s still code that creates an instance of a particular model. But with the intervening syntax, this would be a difficult case to find with grep.
Static config
At Stripe, where I work, we have a lot of code for jobs that need to run at certain times each day. For example, we might need to move funds from one financial partner to another at noon UTC each day. Each of these jobs has configuration code describing when and how it should be run, implemented as a DSL. This config might look something like this:
run_config RunConfig.new(
job_name: 'partner-daily-funding',
env_vars: self.config_env,
cron: RunConfig::Cron.new(
schedule: { hour: 12, minute: 0 }
),
owning_team: Company::Team::Liquidity
)
In our codebase, we have hundreds of these jobs, each with their own run_config. If you look at this codebase as a database, you can imagine these jobs being rows in a jobs table, where the fields on each row correspond to the parameters provided to the RunConfig class.
Wouldn’t it be great to be able to browse all these jobs in a table? Maybe you could perform some basic operations on this data: searching for specific jobs by name or owning team; sorting by the time-of-day they’re scheduled to run; filtering for jobs owned by your team that have errored in the past week. Maybe you could edit the run_config from that interface (like you might edit a spreadsheet) and have it automatically make the corresponding change in the source code (or open a PR). Maybe you could even compute some aggregations on this data — for example, if you’re introducing a new job that requires some expensive computation, maybe you’d like to know which hours have the fewest other jobs scheduled. And of course, this job browser should be bidirectional with respect to the codebase — there should be a button beside each entry that shows the code for the job inline or opens the corresponding code in your editor.
Diffused concepts
Codebases typically contain logical concepts that are implemented across multiple pieces of code. This is often the case when you need to create multiple files to implement a particular feature.
For example, in Rails, a “resource” is collectively implemented across a line in the router, a model file, a controller file, and a bunch of view files. Rails even ships with a code generator to create some of these files for you. But despite resources being a core concept when working with Rails, there’s no good way to browse the resources in your codebase4. There’s no good way to filter or query your codebase either — you can’t, for example, see which resources support JSON vs XML params.
For another example, consider pubsub (aka emitter-consumer) pipelines. In web services, when you have processing that can happen “in the background”, one service will publish an event; another service subscribes to that event and will do the background processing on its own when it receives the event. Often, these will form event “pipelines” or trees where an event consumer will emit additional events that are consumed by yet other services. These pipelines are concepts that developers talk about (as in, the “account creation pipeline” or “funding reconciliation pipeline”), but in most codebases the pipeline itself isn’t declared or reified anywhere in the code.
If you’re looking at code that emits an event, how do you find the consumers? If you’re lucky, the event has a unique, literal name and the consumer uses that name literally as well. But maybe some subscribers are using wildcard event names, or names generated by string concatenation, and that becomes a lot harder to grep for. Likewise, if you’re looking at a consumer of an event, how do you find the locations in the codebase that could emit that event5?
Wouldn’t it be great to be able to browse those pipelines in a table or perhaps a directed graph6? Maybe that graph would support some basic operations on this data: searching for specific publishers or subscribers by class name or event name; filtering for pipelines that have run into errors; maybe even showing the flow of a particular event given an event ID7. And of course, this pipeline browser should be bidirectional with respect to the codebase — there should be a button beside each graph node that shows the code for the publisher or subscriber inline or opens the corresponding code in your editor.
For a final example, consider code that has functionality inherited from elsewhere. Some environments let you see a list of inherited properties or methods, but this isn’t possible for more specialized cases. At Stripe, we have code that implements shell scripts that can take command-line arguments and flags. These arguments are defined via a DSL in the implementing code, but these commands can be subclassed, and there’s no way to see what the available arguments are while working in the subclass.
Philosophy
I think it’s important to consider these problems not as disparate cases in need of bespoke tooling, but as a class of problems characterized by a lack of access to the data structures embedded within codebases. Just like SQL databases and spreadsheets provide a singular querying abstraction and a set of visualization primitives that can be applied to any kind of data, programming environments need a singular querying abstraction and set of visualization primitives that can be applied to the concepts lurking in codebases. Getting there does not mean using proprietary drag-and-drop visual programming interfaces where the introspection capabilities are limited to whatever the programming environment happens to have implemented. Just the opposite — you should still be able to do whatever you want with your code (including treating it as plain-text files), and also have access to more advanced introspection tools that can query and slice your code — tools that let you easily understand and navigate complex codebases to reduce the incidental complexity of building software.
Solutions
I don’t have a solution to sell you here (at least, not yet!). But by popular demand I think it’s worthwhile to at least discuss principles that solutions should embody and directionally-related prior art.
To start with a simple example, see IHP, a full-stack web framework similar to Rails. It comes with a web interface for manipulating your project’s codebase and database schema. One point in the introduction video showed changes being made in the visual schema editor being automatically reflected in the SQL code that describes the database schema — and changes being made to the SQL code being bidirectionally reflected in the visual schema editor.
For a more in-depth example, consider Pharo, a Smalltalk environment. “Environment” in this case means that it feels like you’re using a custom OS (including global menus, idioms, and keyboard and mouse conventions) designed specifically for browsing, writing, and debugging programs in the Smalltalk programming language8. The holistic integration of these tools is important. Unlike the programming environments we cobble for ourselves today — where the editor is agnostic of the language and runtime and other tools like debuggers, inspectors, and code browsers are tacked on (if they exist at all) — it’s worth thinking about what an entire computing experience for writing and building custom tools might look like9.
Pharo is also interesting because of its Class Browser, which looks like this:
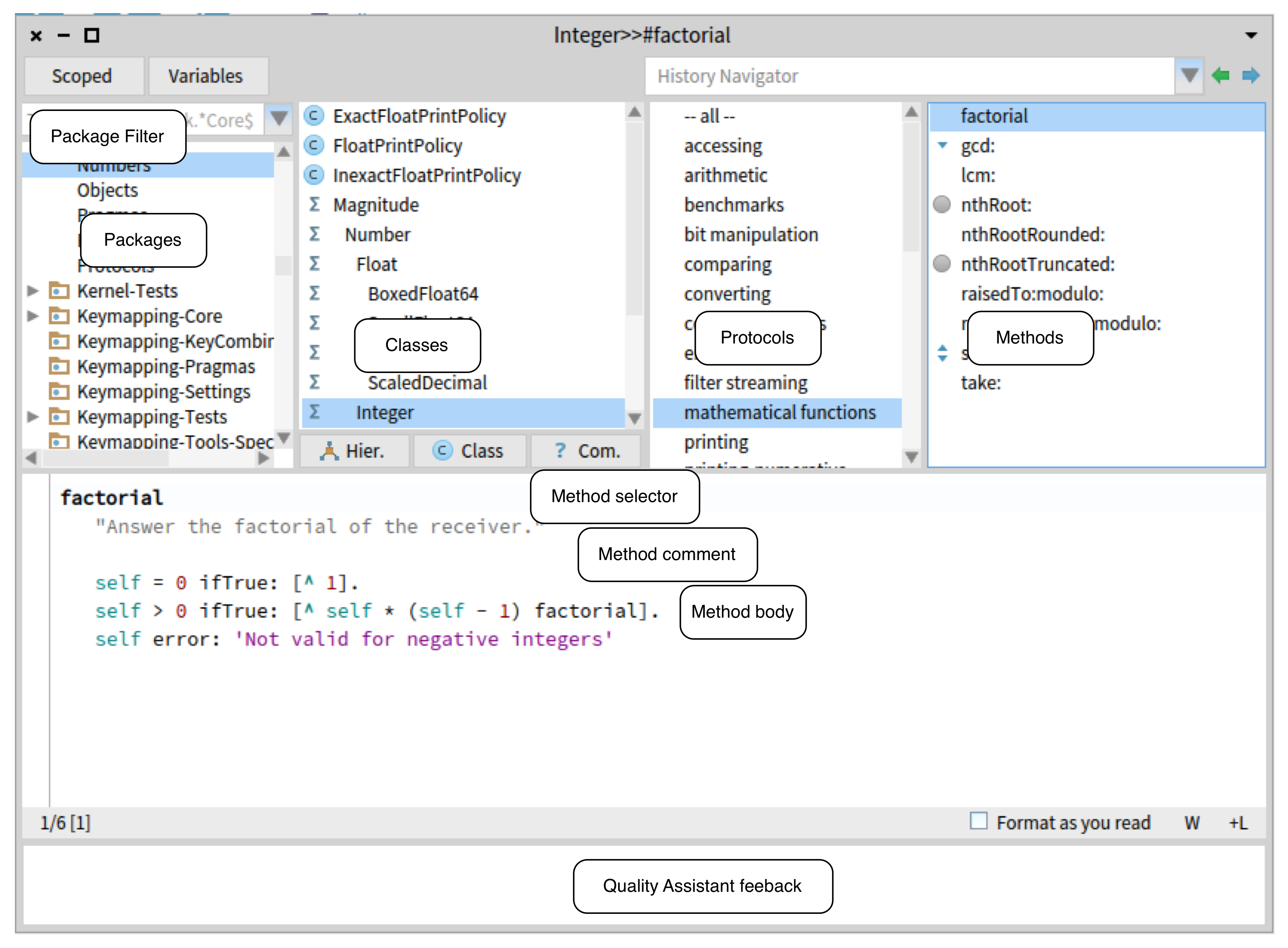
This browser breaks free from the source code file as the atomic unit of browsing; instead, it allows the user to browse one method at a time. Making the “unit of browsing” smaller enables more interesting remixes. In the screenshot below, searching by method name returns a list of matching method names with implementing classes nested below each. This is the inverse of the hierarchy shown in the Class Browser.
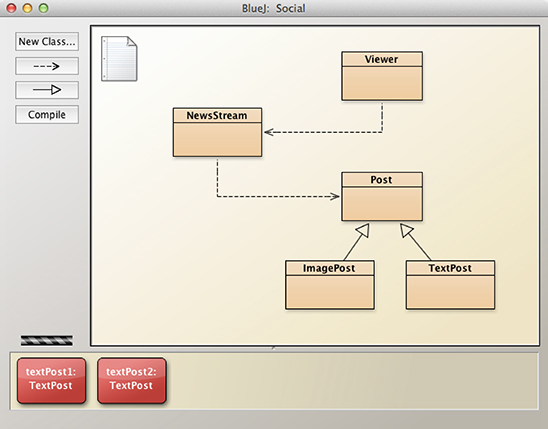
Breaking free of text-filled files enables visualizations — the kind you might draw by hand to describe a system — that is automatically kept updated with the code. These diagrams can be both read-interactive and write-interactive — the former referring to different ways you can arrange the visual content, and the latter referring to changes that can be made to the visualization and reflected back in the underlying code. BlueJ is a Java development program that implements this idea. Its primary interface is a UML-like diagram of the classes that comprise the program, with arrows indicating “extends” or “uses” dependencies between the classes. You can add arrows directly in the diagram, in which case the source would be automatically updated, or you can update the source (with extends or implements definitions, or import statements), and the corresponding arrows would appear in the diagram10.
Also consider Glamorous Toolkit, a programming environment for building custom tools and visualizations. Glamorous Toolkit comes with a very extensive “standard library”, including graphic visualizations and parsers for some programming languages like Java. These parsers turn source code into native data structures that can be manipulated with standard methods — for example, the Java parser creates a standard list of class objects; you could then use built-in list methods like select to filter it. This allows you to arbitrarily query the codebase. These queries can then be visualized with different types of graphs and diagrams to better understand what’s happening. This post walks through extracting and visualizing the use of @deprecated classes in large Java codebases11.
Glamorous Toolkit is notable for at least two reasons:
-
It provides tools to build parsers for code (and includes some parsers out of the box). Parsers in general turn code from strings of text into native data structures. Parsers can also be built specifically to recognize application-specific constructs. For example, given the
run_configexample above, a generic Ruby parser would turn that block of code into a “method call” object, but a custom parser could be written to turn that block of code into a specialized “run config” object with relevant attributes. - In addition to integrating parsers, Glamorous Toolkit also integrates graphics code and output, making it easy to construct diagrams to visualize the problem space. The alternative would probably be creating a new project in a separate codebase, then choosing and installing a graphics library, and finally figuring out how to export output from the parser and import that data into this new codebase — all before being able to visualize it. That’s a lot of incidental complexity. In contrast, a programming environment that integrates a wide range of tools reduces this overhead and pays off each time you want to “just try something”.
Glamorous Toolkit integrates many basic tools in an attempt to make it easy to build domain-specific tools that can be used to better understand a codebase. But, I contend, codebases and tools have the inverse of the hammer-and-nail problem — that is, when all you have are nails, it’s hard to build tools that can do much with them. A codebase, defined narrowly as a bunch of text in human-organized files and folders, is as primitive as a box of nails. Software tooling, by and large, does little to automatically illuminate the large-scale structures of the codebase they act on.
If a codebase is a primitive construct, what’s the “high-level language” complement? One possibility: a program could be built by defining the types of constructs it would have — API endpoints, data models, job run configs, pubsub pipelines, shell scripts, and so on — and the properties and required methods for each construct. Properties for an API endpoint might include its HTTP method, URL, a list of input parameters, documentation name, and description. It might have one required method called execute. Creating a new API endpoint in a program would involve creating a new “instance” of this construct, filling in the required fields, and coding an implementation for the execute method.
This approach certainly isn’t perfect. Of the examples we’ve considered, it may not provide enough granularity to figure out “where is this used”. But I think it’s directionally-correct because of the following properties:
The user interface for programming this way is an open question but, encouragingly, I don’t think there’s only one right way to do it. This “data entry” model of programming reifies the database-within-your-codebase, and in the same way that the vast majority of programs are just fancy ways to read and write records from a database, there will be just as many ways to create and browse database-codebases.
The database-codebase can eliminate a lot of incidental complexity required to understand a codebase — namely, the need to parse the text and/or implement some amount of metaprogramming to keep track of DSL usage. This makes it easier to compile different views of this data. For example, you could map over all the API endpoints to generate API reference documentation (complete, of course, with bi-directional links from a documentation page back to the relevant code entry). With the addition of some foreign-key references to the database-codebase schema, you could generate architecture diagrams that are automatically kept in sync with the code. With some string interpolation, you could even generate folders and files full of source code, in any programming language syntax you’d like.
Thanks to Hirday Gupta and Long Tran for reading early drafts and suggesting edits. Cover photo by Joshua Sortino on Unsplash.
-
Specifically, I mean that the baseline for querying a codebase is usually regex-powered searches through an editor or a hosted tool like Livegrep.↩
-
E.g. the
UIprefix inUIKitclasses.↩ -
E.g. suffixing
Controllerto the class names of controllers in an MVC-based codebase.↩ -
The top StackOverflow answer for “rails list resources” involves some regex wrangling on the router file.↩
-
This point generalizes beyond literal pubsub system. Hirday reminded me that this is also true for Redux actions and reducers (e.g. given an action, where is the reducer code that consumes it? Given a reducer case, where is the code that emits that action?).↩
-
Many pubsub systems use string keys, and strings can be manipulated at runtime, so this is admittedly difficult. It would require a combination of static code analysis and runtime tracing.↩
-
In other words, distributed tracing.↩
-
At the risk of glamorizing historical constraints, the early days of UNIX worked like this. Ken Thompson wrote: “
ccis the compiler for the C language, which is the axis around which all of UNIX resolves. UNIX itself is written in C, as are the Shell, C, and about 70% of the system commands.” C’s standard library was the OS’s standard library.↩ -
Paraphrased from Section 5.3 of the tutorial (page number 21).↩
-
The initial “Setup” section introduces some other libraries that aren’t directly relevant to the post’s main point. At the end of that section, there’s a list of all the classes in the loaded codebase, and the “Locating deprecated classes” section picks up from there.↩