Viewing iMessage History on a Computer
I occasionally want to go back and browse conversations I’ve had, either to lookup some detail or to revisit a discussion (many of which might become future blog posts 🙃). Aside from work Slack, the vast majority of my conversations are through iMessages, but Apple’s apps don’t make it easy to scroll through history. I figured it would be fun to write my own. The first version is the equivalent of one day’s work, and everything is available on Github.
The rest of this post will walk through the code and my thought process as I went along. When I was learning to program, I would come often across projects where I didn’t know enough to begin to understand how I might build something similar, and I wished that the author would have explained the thoughts that took them from A–Z. This is the sort of guide I would’ve wanted to read.
Sketches
Since I’m building this project for myself, I started by defining some criteria:
- It should be really easy to build. I wanted this to take about a day, not drag out over weeks or months.
- A web UI would be much easier to build than a native UI.
- I write a lot of Javascript at work, and I wanted a break from JS — this project should have as little JS/frontend scripting as possible.
- I wanted to play around more with Crystal (a programming language).
- The interface could be bare-bones, since it was more important to me that I finish quickly than make something beautiful.
-
I wanted the product to behave in a way that’s “native” and familiar to me. In particular, that meant that
- Links should load immediately
- Back and Forward should work
- I could use Cmd+F to quickly find anything. This also meant that I wanted all messages to be on one page, rather than have pagination.
- I wanted to be able to use the arrow keys, spacebar, and Page Up/Page Down keys to scroll the messages (not the list of messages), since most of my use case would be reading the messages in a particular conversation.
- I should be able to link to any conversation or specific message.
I started with both technical criteria and user-experience criteria. Since this is a project for myself, and partly intended as a technical exercise, it’s roughly a 50/50 split. If you were building a robust product for other users, the user-experience criteria would probably comprise most of the requirements. If you were building a technical proof-of-concept, the technical criteria would dominate (although it’s still important to consider how other developers might use it — what you might call the developer experience).
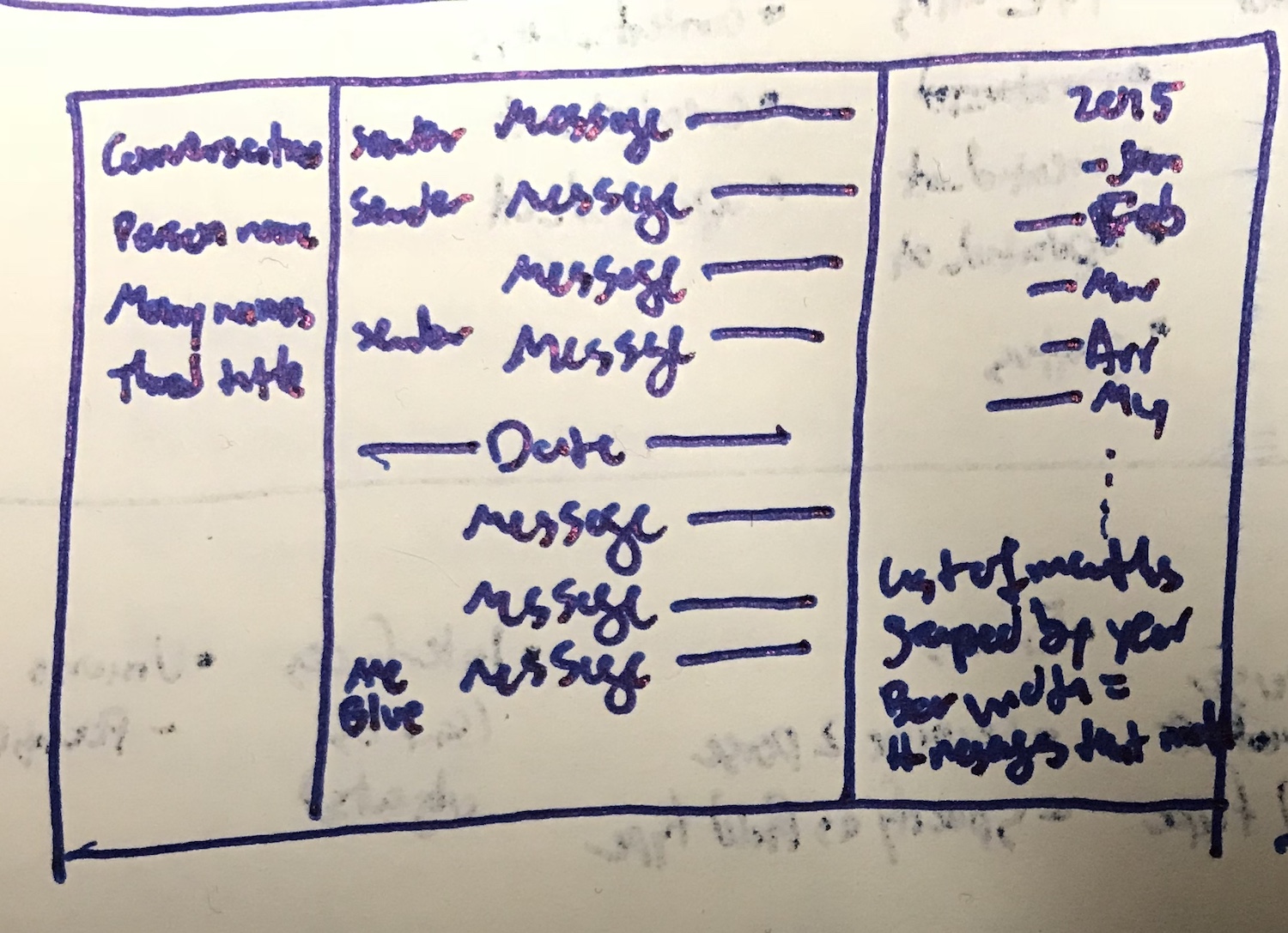
I also drew a rough sketch to offload my interface ideas from my working memory.
Loading a list of conversations
I started by loading all my conversations. This simple step helps me build momentum, and is directly useful.
From prior experience, I knew that my messages were saved in a SQLite database at ~/Library/Messages/chat.db (this is also easily Googlable). I decided to copy this file to a temporary location when running my app so I could avoid any accidental data damage. I was also concerned that read locking might be an issue, but that doesn’t appear to be a problem.
Since messages are stored in a SQLite file, loading a list of conversations meant making a SQL query and loading the results into some data structures. Crystal is an object-oriented language, so I started by figuring out what objects I wanted to have; at this point I wasn’t concerned with the fields or methods they would have.
The models (Chat and User) were obvious. Besides that, I knew I wanted a place to put all the code involved in actually working with the database — opening the file, executing a query, and cleanup (closing the file). In OOP design, “a place to put code” is often an object — hence the Database class. Similarly, I wanted a place to put the SQL query (hence Queries::AllChats), and a place to put the code that would run the SQL and instantiate my models (hence ORM::Chats). The module namespacing isn’t required, but I find it helpful to organize my code.
Arguably, a class to manage a SQL query could be considered unnecessary; a SQL query is simply a string. However, developers tend to think of a SQL query in more structured terms — selecting a set of fields from some (joined) tables, possibly with a WHERE criteria or a sort order. Creating a class allowed me to break apart these components, and, in my opinion, improves developer ergonomics. If I wanted to change the selected fields, it’s much easier to edit a method than to fiddle around with a string.
# View raw: https://gist.github.com/feifanzhou/cc97abcfcc3a4206caa2e740c6b2864f
module Queries
struct AllChats
# Table aliases:
# C => chat
# CHJ => chat_handle_join
# H => handle
def sql
"#{select_clause} #{from_clause};"
end
def read_types
{
row_id: Int32,
chat_identifier: String,
service_name: String,
handle_id: String,
}
end
private def fields
%w[
C.ROWID
C.chat_identifier
C.service_name
H.id
]
end
private def select_clause
"SELECT #{fields.join(", ")}"
end
private def from_clause
"FROM chat C " \
"JOIN chat_handle_join CHJ ON C.ROWID = CHJ.chat_id " \
"JOIN handle H ON CHJ.handle_id = H.ROWID"
end
end
endA nice benefit is that there’s now an obvious place to define the expected types that I’ll get back from the database.
To determine the query itself, I used SQLite Browser to look at the data and schema. It includes a REPL which allows me to quickly try queries until I got the results that I was looking for.
Being able to run code and see the results rapidly is crucial to effectively writing software.
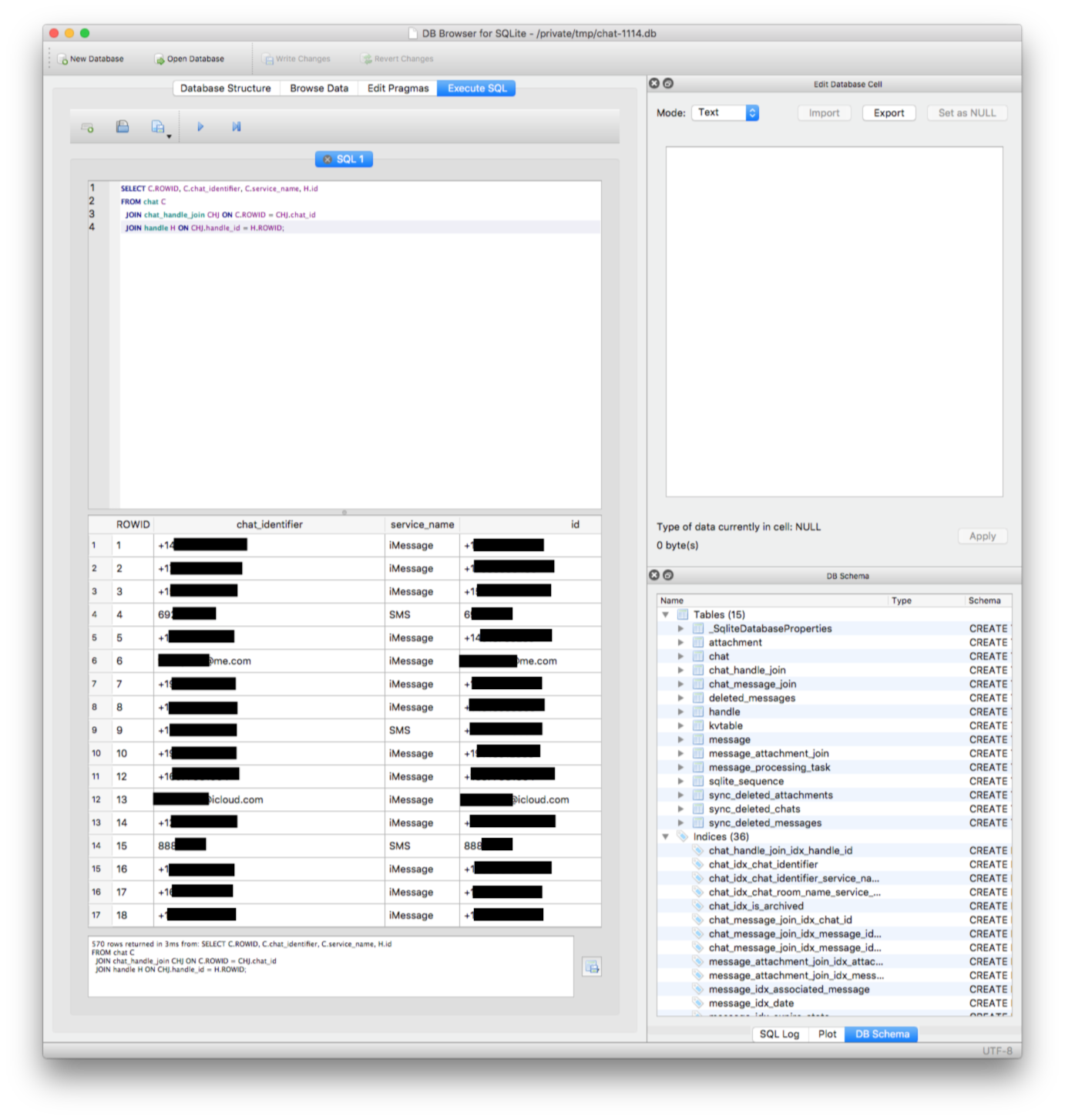
In practice, I started by looking at the structure of the tables and browsed the data to get a sense of what the data looked like — how did they store phone numbers? Were IDs integers, UUIDs, or something else?
The aptly-named chat table looked promising, and contained almost everything I was looking for. However, it wasn’t a perfect data source for the phone number or email of the people I was chatting with:
-
The GUID column contained values like
iMessage;-;+15551234567, but I didn’t want to do string manipulation on this value because I didn’t want to rely on the format of the string. Generally, when working with someone else’s system, it’s a good practice to treat ID strings as opaque, rather than trying to decipher their internal structure. -
The
chat_identifiercolumn had useful values most of the time, except for group conversations where it contained an auto-generated value likechat86732149616291698(this was also present in theGUID).
Fortunately, when I began this project, I had been googling for some background on working with iMessages data, and came across Steven Morse’s article which started with the handle table. This table contained the specific phone number or email for everyone I’ve messaged, and the aptly named chat_handle_join table brought them together. A couple of REPL iterations later (it took me a few tries to figure out which columns were the relevant foreign keys), I had a working SQL query.
chat_handle_join is a SQL join table; join tables are used to implement one-to-many or many-to-many relationships. For example, one chat can have many handles if it’s a group chat. The chat table has one row for the chat, the handle table has one row for each handle, and the chat_handle_join table has one row for each handle with a corresponding chat ID.
Turning chat handles into contact names will be covered a few sections below.
Finally, I added some code that would run everything and output the intended result: a list of Chat objects. This allowed me to setup a rapid feedback loop for my app code — I kept a Terminal tab with crystal src/messages_browser.cr in the history, and every time I made a change, I brought up that command and ran it.
Loading messages in a conversation
This step followed the same thought process as the last step. The message table data looked promising. Following the same pattern as the handles above, the chat_message_join table handled the one-to-many relationship between a chat and its messages. message.handle_id pointed to a handle, representing the message sender. Conveniently, message.is_from_me made it easy to identify “my” messages and display them accordingly.
However, the dates on each message looked unusual to me, and I spent a while figuring out how to work with those values. The date column contained values like 530402579000000000. All the dates ended in 9 zeros, so when playing around with the value, I started by dividing them all by a billion. Comparing dates on two messages to known timestamps (mousing over the corresponding messages in the Mac app), the numbers (sans zeros) corresponded to seconds, but they didn’t look like Unix timestamps which, for recent memory, started with a 1. Fortunately, I did some iOS programming years ago, and remembered that some of Apple’s API use midnight on January 1st, 2001 as an epoch time. That time translates to 978307200 seconds after the UNIX epoch (January 1st, 1970), and adding this number to the date value resulted in a timestamp I could work with.
I probably could’ve done this transformation in the SQL query, giving my app nice numbers back. But I didn’t, because:
- I’m not very familiar with the SQL syntax for doing so, which would’ve made the code more likely to have a bug and be harder to maintain.
-
Similarly, it’s easier to have that code in app-code. For example, the transformation is more reusable — by adding the method to the built-in
Timeclass, I can use it anywhere else timestamps like this are stored. If this was a team project, it makes it easier for other team members to work with because they won’t have to work with the relevant SQL as well as the app code that they already have to understand. - In a production environment, app code typically scales better than database code. App code can scale horizontally (adding more servers) or vertically (using beefier servers); scaling a database generally isn’t as easy. It’s not a real issue for a project like this, but I think it’s still a relevant “best practice”.
Rendering UI
Once I had the data I needed, I could start building my UI. I decided to use Kemal for its simplicity. Intuitively, I only needed two pages — one to list my chats, and one to list the messages for each chat. With the Database class encapsulating all access to the database, the app server was really simple:
# View raw: https://gist.github.com/feifanzhou/ed5a462598daa9231b832c44262a21e1
require "kemal"
require "./*"
print "Starting…\n"
print "Opening database…\r"
db = Database.new
print "\e[KDatabase ready\n"
get "/" do
chats = db.all_chats
render "src/views/index.ecr", "src/views/layout.ecr"
end
get "/chat/:chat_id" do |env|
chats = db.all_chats
chat_id = env.params.url["chat_id"].try(&.to_i)
messages = db.chat_messages(chat_id)
render "src/views/messages.ecr", "src/views/layout.ecr"
end
Kemal.run
The print statements aren’t strictly necessary, but it adds a nice touch to the user experience when starting the app, especially if it takes a moment to load the database.
As for the output syntax: \n prints a line break. \r is a carriage return — it moves the cursor to the beginning of the current line, so any subsequent print output would overwrite the current line. \e[K is a Bash control character that clears the current line first.
The views themselves are straightforward — they iterate over chats and messages respectively and output a DOM element for each. The messages page also includes the list of chats; I didn’t find any apparent solution to avoid duplicating the view code there, but I could live with a few copy-and-pasted lines.
The only interesting thing in the CSS is creating a separate scroll container for the chats list, which allows keyboard scroll commands (spacebar, arrow keys, Page Up/Page Down) to scroll the messages list.
A few UI tweaks followed: adding timestamps, making it easier to visually browse messages; changing the color of the messages I sent to make it easier to read the conversation (bubbles would’ve been too fancy); highlighting the currently selected chat in the chats list; and escaping message text (which I only remembered because I noticed some messages rendering strangely as a result of a literal <div> I’d written in the original message text). These changes aren’t very interesting.
Displaying contacts names
View on Github (this commit also contains changes for attachments, covered below. Sorry for the Git sloppiness).
This was the hardest part of the project. iMessages doesn’t know anything about contacts’ names; that’s managed by the OS’ AddressBook framework and the Contacts app. I figured the underlaying data was likely stored in a SQLite database somewhere. I had a little difficulty finding it, but some Googling revealed that the database was in ~/Library/Application Support/AddressBook. One twist from many of the existing articles was that, because I sync my contacts through iCloud, I had a Sources folder with two subfolders (labelled by UUIDs), one of which corresponded to my “On My Mac” contacts, and the other with my iCloud-synced contacts. The filename is AddressBook-v22.abcddb in both folders, and it’s a SQLite database. Rather than worrying about how to determine the relevant source UUID, I just loaded all the databases.
At first, looking at the data in SQLite browser, I wasn’t clear how the schema worked. I then considered working with the native macOS AddressBook.framework — preferably a low-level C version, which would be easier to bind in Crystal. However, a lack of relevant documentation (and seeing the amount of boilerplate needed to work with Foundation and CoreFoundation data types) made that approach seem like a bad idea.
Luckily, I stumbled across an old Macworld article containing SQL code to search the database. The code still works, and revealed enough about the database schema for me to figure out the query I needed to return a contact’s name given an email or phone. A couple of iterations in SQLite Browser later, I had the query I needed. I also created a Contacts class, similar to the Database class, to manage access to this database.
I decided the simplest way to use it was to add a method to the User model, which I was already using in the Message and Chat classes. This came from thinking about developer ergonomics — any class that worked with Users don’t have to also know about Contacts. For example, Chat could implement display_name with a short, elegant map rather than having to know about how the Contacts class works. This is used when rendering the list of chats.
Display attachments
Early on, I wondered how non-textual messages (photos, links, etc) were handled. I was reminded of this thought when I noticed some messages that had no text, and realized that attachments were the missing piece. I found this article (caution: slow site), which helped me understand the data schema. A message can have multiple attachments, and they’re linked via the message_attachment_join table.
I took the query that loaded messages, and made some changes to also load attachments. My first attempt returned a few dozen rows for a conversation I knew had hundreds of messages. I realized I need a LEFT JOIN, which would include all rows from the message table (since it was on the “left” side of the join), even if it didn’t have any attachments. A plain JOIN would’ve been an INNER JOIN, which only returns rows that have both a message and an attachment.
A join like that returns one row per message or attachment, which meant that for messages with multiple attachments, I’d get multiple rows for the same message. The code that creates Message instances had to take that into account — it keeps a hash of Message instances, keyed by its ID. If I came across a result row that referenced the same message, I’d append the returned Attachment to the Message. Otherwise, I’d create a new Message and add it to the hash. The method returns the values in the hash to keep its external API consistent.
The last interesting piece is the MessagePresenter class. Generally, a presenter is a class that translates from a data object to an output — often to a JSON or HTML string. In this case, MessagePresenter is initialized with a Message and figures out the HTML output for the message’s contents. If it has attachments, the presenter returns some links; otherwise, it returns the (escaped) message text.
(I’m a fan of the Presenter pattern. I’ll probably write another post on their benefits and how we use them at work).
Wrapping up
All of the code is available on Github. The project does everything I need it do for now. I don’t feel compelled to constantly update it; it may be weeks, months, or years before I make any changes. Bugfixes notwithstanding, I consider it a v1 and done.
I wrote this post because it’s what I would’ve wanted to read if I came across a project like this, made by someone else, and I didn’t know enough to build it myself. I’ve read a lot of technical blogs that didn’t dive into the level of depth I craved, especially about specific implementation details, nuanced decisions, and the underlying thought process. As someone who’s relentlessly curious, I was (and continue to be) hungry for richly tactical explanations. This is an attempt to put something like that out there on a topic I now know a little about. I hope someone finds it useful.